In a previous post, @Sw4mp_f0x and I discussed the importance of data parsing skills for penetration testers and detailed the basics of how to get started with it. In that post we covered multiple ways to match text and search for specific strings. The examples we used were pretty straightforward, which is not always true to life. In this post we will cover more advanced pattern matching with regular expressions, giving you even greater control and flexibility over your parsing tools.
Regular Expressions
A regular expression, often referred to as regex, uses metacharacters, wildcards, and literal characters to define patterns that can be used with a wide range of Unix and Windows tools. Sounds simple, right? Regular expressions can prove to be difficult, especially when just starting out. Luckily, there are a wealth of resources to help out in a pinch. To complicate things even further, regex syntax will vary by tool or programming language. For example, regex developed for use in Python may not work in awk.
To use an overly-simplified example, let’s say we want to write a regex to match the words car and cat. Logically, you would want to match a word that starts with the letters c and a and ended with the letters r or t. In regular expression syntax, that looks like:
Syntax explanation:
and is followed by the letters "r" or "t" at the end of the line.
Here is a table with common metacharacters supported by awk and sed:
| Character | Description |
|---|---|
| . | Matches any single character (or newline) |
| * | Matches preceding character or metacharacter zero or more times |
| \ | Escapes a special character, causing the tool to treat the following character as literal. When in doubt, escape it. |
| ^ | Matches the beginning of a line |
| $ | Matches the end of a line |
| \b | Word boundary (beginning or end) |
| [...] | Matches any one of the characters contained within the brackets. Also supports a range, such as [0-9] or [a-zA-Z]. You can also match character types by specifying a character class |
| [^...] | Does not match any of the included characters or ranges. The opposite of [...] |
| + | Matches preceding character or metacharacter one or more times
(Extended metacharacter) |
| ? | Matches the preceding character zero or one time
(Extended metacharacter) |
| | | Acts as a logical OR on multiple regular expressions
(Extended metacharacter) |
| (...) | Used to group regular expressions, such as when using the | metacharacter. Expression matches within a group can be called later on.
(Extended metacharacter) |
| (?:..) | Passive group. The value of the expression match is not stored for later reference
(Extended metacharacter) |
| {...} | Denotes a range for the previous character. Follows one of the three following formats:
|
For more detailed information about these metacharacters, see the GNU Awk User’s Guide.
It’s important to note that not all metacharacters are supported by all tools, particularly those marked extended metacharacter above. If you are running into errors or improper matching, check that the syntax is supported by the tool or operating system you’re using. When working with grep, make sure to use the -E switch to enable use of more regex metacharacters, such as the curly brackets. Additionally, in order to use a metacharacter literally, you must escape it with a backslash. Yes, even the backslash itself if you need one in your pattern.
To really see regular expressions in action, let’s work through a basic example. You have been given several files from your client and told that they contain all of the used IP addresses and IP ranges in their network. They can’t be bothered to format the files into a usable format.
Here is the content of the provided files concatenated into one:
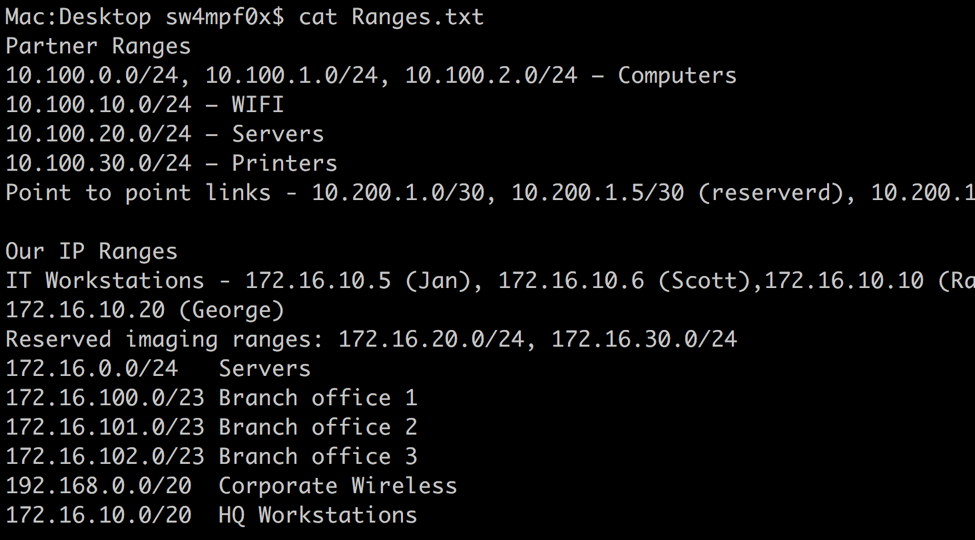
Within this file we have individual IP address and IP address ranges and we want to extract both in order to ensure we test everything. We can use grep, awk, or sed to do this. Let’s go with grep for this example. As with many things, there is more than one way to go about this. We use the -o switch to output anything that matches the regex. Default behavior is to print the entire line that a match is located in. The following will work well for this example:
grep -o -E '[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}(?:\/[0-9]{1,2})?' Ranges.txt
Breakdown: [0-9]{1,3} - The brackets define a range of characters that will match. Here, any number 0-9 will match. The curly brackets are used to define the number or range of acceptable repetitions of the previous expression. In english, this matches 1 to 3 sequential numbers, which is what an IP address octet will fall into. There are 4 of these expressions in the regex above, one for each octet, separated by an escaped period. The period must be escaped because it is a metacharacter that would otherwise represent any character other than a newline.
(?:\/[0-9]{1,2})? - With this we provide an optional expression for CIDR notation in the form of a passive group. Passive groups are defined with (?:….). A non-passive group, called a ‘named group’ is different and can be referenced later on. More on this later. The passive grouping allows us to apply a quantifier (+, ?, {}, *) to a group of expressions. Quantifiers apply to the previous expression, in this case a passive group. We use the question mark quantifier to make the entire passive group optional. The group contains an escaped forward slash and 1 to 2 digits (0-9), just like we did for the octets.
Let’s take a look at this in action:
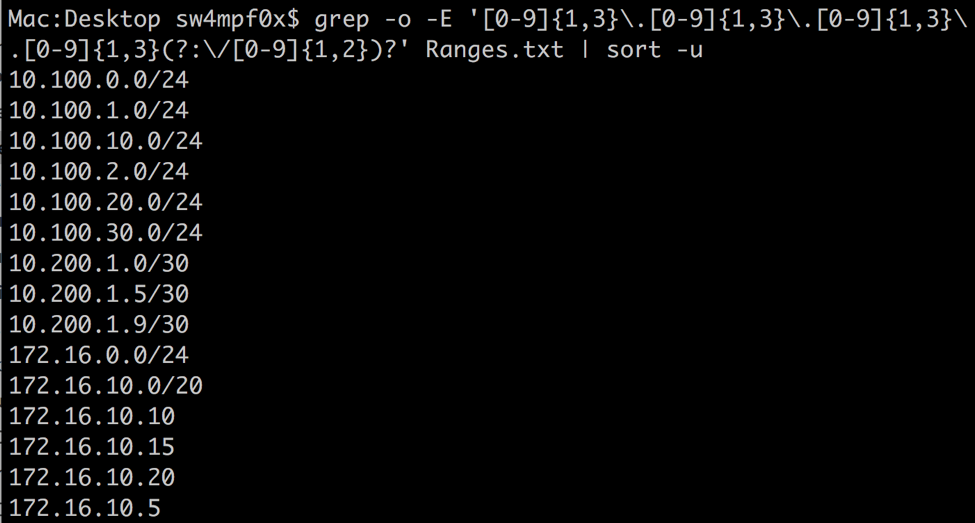
This meets our needs for this case, but can be prone to false positives. For example, the invalid IP address 10.0.15.467 would match with this regex. Let’s make this a little more granular using a couple more metacharacters. First, I have inserted a couple of invalid IP addresses.
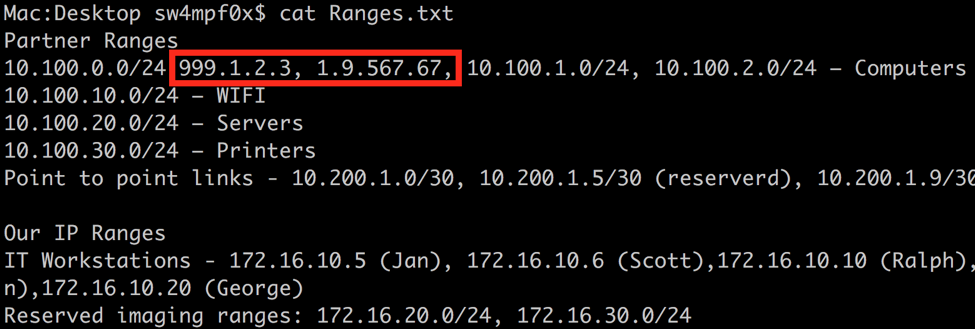
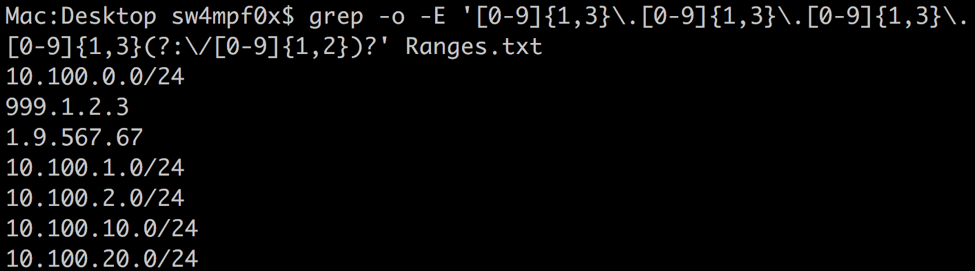
As you can see, our current expression happily matches the invalid IP addresses. The first thing we can do is be more specific with what numbers are allow. We can use the | metacharacter to give the expression several options to match for each octet:
(?:25[0-5]|2[0-4][0-9]|1[0-9]{2}|[0-9]{2}|[1-9])\.
Within this passive group, there are five possible expressions that can be match for each octet:
- 25[0-5] (250-255)
- 2[0-4][0-9] (200-249)
- 1[0-9]{2} (100-199)
- [0-9]{2} (10-99)
- [0-9] or [1-9] (0-9 or 1-9 for the first octet)
Including these inside a passive group and separating them with an ‘or’ metacharacter | creates an expression that will match the values you would expect from a valid octet, 0-255 or 1-255 for the first octet. Now if we replace our octet expressions used so far, we get a much longer regex that eliminates most, not all, false positives that may be encountered. Note that the first is slightly different to restrict a ‘0’ value.
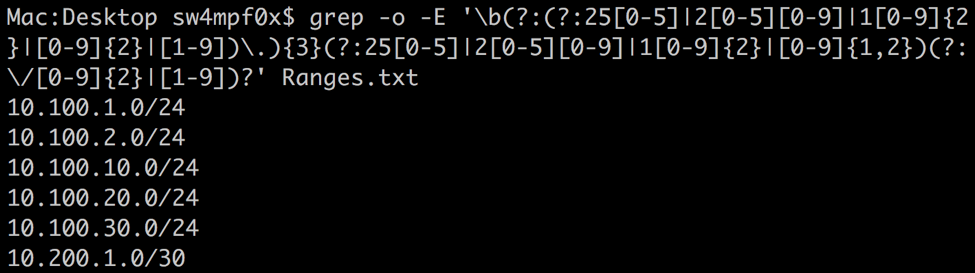
In the previous screenshot, you will see the IP address 999.1.2.3. This will still be accepted as a valid IP address by excluding the first ‘9’. We can prevent this with a word boundary metacharacter. Similar to the ^ and $ metacharacters, which matches the start or end of a line respectively, the word boundary metacharacter \b matches the beginning or end of a word. Interestingly, numbers act as words in the context of word boundaries.
The result:
Lookahead and Lookbehind
Lookaheads and lookbehinds determine if a pattern follows or precedes the define regex. Each comes in two flavors: positive (pattern does appear) and negative (pattern does not appear). A key difference between lookaheads and lookbehinds is that lookaheads can test for a search pattern or regex, whereas a lookbehind can only use a search pattern.
Here is the syntax for each:
| Description | Syntax |
|---|---|
| Positive Lookahead | (?=string) OR (?=(regex)) |
| Negative Lookahead | (?!string) OR (?!(regex)) |
| Positive Lookbehind | (?<=string)</i> |
| Negative Lookbehind | (?<!string) |
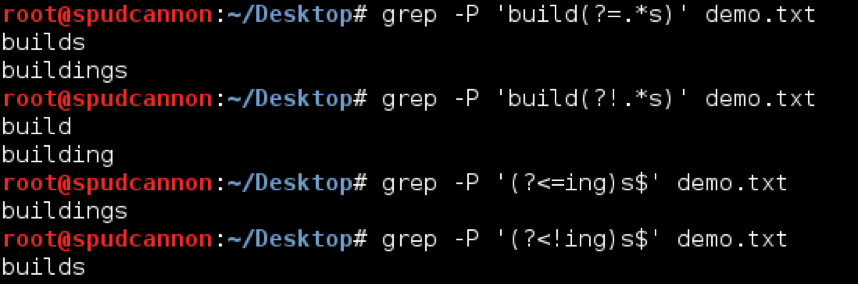
Consider the following word list:
build
builds
building
buildings
Here is a demonstration of using each lookahead and lookbehind to match this list. Note that we are using the -P flag with grep. Without that flag, lookaheads and lookbehinds would not work. If you have issues with these, ensure your tool supports lookaheads and lookbehinds.
Backreferences
Backreferences allow a regex to match a previously matched pattern earlier in the regex. For example, in the sentence “word is the same as word,” where word can be any value but where both occurrences must match. Backreferences rely on capture groups to assign variables properly. A capture group is any regex surrounded by parenthesis. Once capture groups are defined, a backreference is used with the \x metacharacter, where x is the capture group number.
To follow the earlier example, the following regex would match only when the first and last words match:
(^.*\b) is the same as \1

Backreferences can be highly useful in pentesting when parsing structured data formats, such as HTML, XML, or log output.
Useful Regular Expressions
Here is a table of some regular expressions that may commonly be needed on a pentest/red team:
| Description | Regular Expression |
|---|---|
| IP Address (with optional CIDR) | [0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}\.[0-9]{1,3}(?:\/[0-9]{1,2})? |
| Internal IPv4 Address | (10\.[0-9]{1,3}|172\.((1[6-9])|(2[0-9])|(3[0-1]))|192\.168)(\.[0-9]{1,3}){2} |
| Domain Name from URL (Requires Lookarounds) | '\b((?<=https://)|(?<=http://))?[a-zA-Z0-9]*\.[a-zA-Z]+(?=:[0-9]{1,5})?(?=/)?\b |
| MAC Address | ([0-9a-fA-F]{2}:){5}[0-9a-fA-F]{2} |
| Domain User | \bDomainName\\\w+ |
| US Social Security Number | [0-9]{3}-[0-9]{2}-[0-9]{4} |
| US Phone Number | (\(?[0-9]{3}\)?)? ?[0-9]{3}[-\.]?[0-9]{4} |
There are many great resources for finding more specific regular expressions you can use to find pieces of personally identifiable information (PII) related to your testing. Here are a couple more for reference:
- Credit Cards by Issuer - regular-expressions.info
- Valid IPv6 Addresses - StackOverflow
- International phone number - StackOverflow
- Mobile User Agent - GitHub - dalethedeveloper
Summary
As you can see, pattern matching can quickly get complicated. But, regular expressions are extremely powerful and can save you a lot of time instead of trying to chain multiple tools together on the pipeline. Regular expressions are supported in some form in just about every tool that provides a search function, so learning how to wield them is well worth the time.
This post was co-written by Jeff Dimmock (@bluscreenofjeff) and Andrew Luke (@sw4mp_f0x).
Please check out Andrew Luke’s blog at https://pentestarmoury.com.
Further References:
- Regular-expressions.info
- rexegg.com
- Regexr.com
- regexpal.com
- Regular Expression Language - Quick References - TechNet
Parsing for Pentesters Posts
- Finding Diamonds in the Rough- Parsing for Pentesters
- Black Magic Parsing with Regular Expressions- Parsing for Pentesters