Covert red team attack infrastructure is a topic I’ve covered many times before, but always only in part. I’ve wanted to write about the thought process behind the design process of attack infrastructure for a while. In October, I had the privilege of covering that very topic at ArcticCon in Minneapolis, a con by red teamers for red teamers. My talk, Building a Better Moat: Designing Effective Covert Red Team Attack Infrastructure, covered the what and the why of attack infrastructure, rather than focusing on the how. In this post, I will discuss attack infrastructure design considerations and expand upon some of the points I made in my talk. If you’d like to learn how to deploy red team attack infrastructure, please check out the Red Team Infrastructure Wiki on GitHub, maintained by Steve Borosh (@424f424f) and me.
The concepts covered in this blog post are inspired by the previous work of many individuals, especially Raphael Mudge (@armitagehacker). Some of those resources are listed in the References section below.
What is a Covert Red Team Attack Infrastructure?
A covert red team attack infrastructure is any back-end component from which a red team is performed. This includes domains, redirectors, SMTP servers, payload hosting servers, and command and control (C2) servers. Generally, a simplified way of thinking of it is that any asset in the attack path not controlled by the target organization or its users. This description, of course, describes any hacking infrastructure. What makes a covert red team attack infrastructure unique are the controls built into the infrastructure to evade detection, hinder incident responders, and maintain resilience throughout the assessment.
For example, a typical penetration test infrastructure may look something like this:
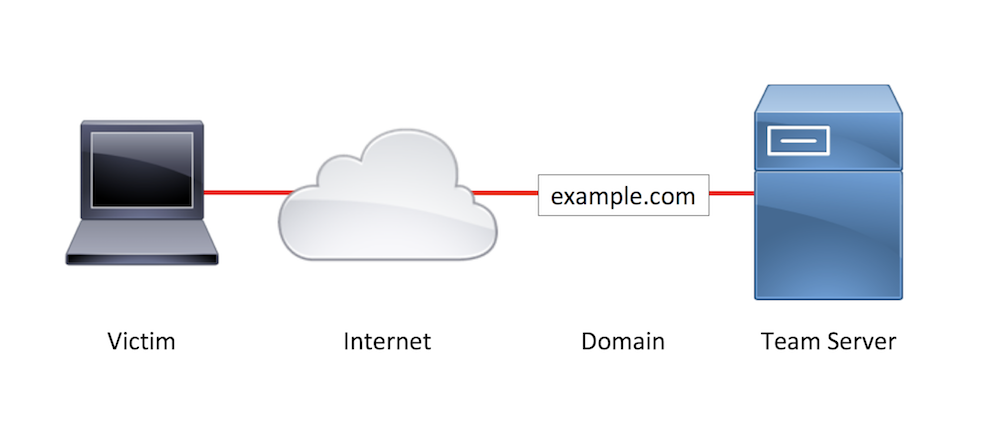
Sample Penetration Test Infrastructure
The attacking server typically performs the function of phishing email origination, payload hosting, and C2. The only asset between the target network and the attack server is a domain. This setup means if any single component of the attack, such as the phishing email, is identified as being malicious, there is a high chance that a large portion of (or the entire) attack will be compromised. Since the phishing emails likely came from the same domain that the payloads were hosted on, which is also where the C2 connects, an email and web block to one domain could shut the whole attack down.
On red team assessments, getting caught is part of the game. In order to persist on the target network and press forward to achieving the assessment objectives, we need a better infrastructure setup.
Here is a sample covert red team attack infrastructure setup:
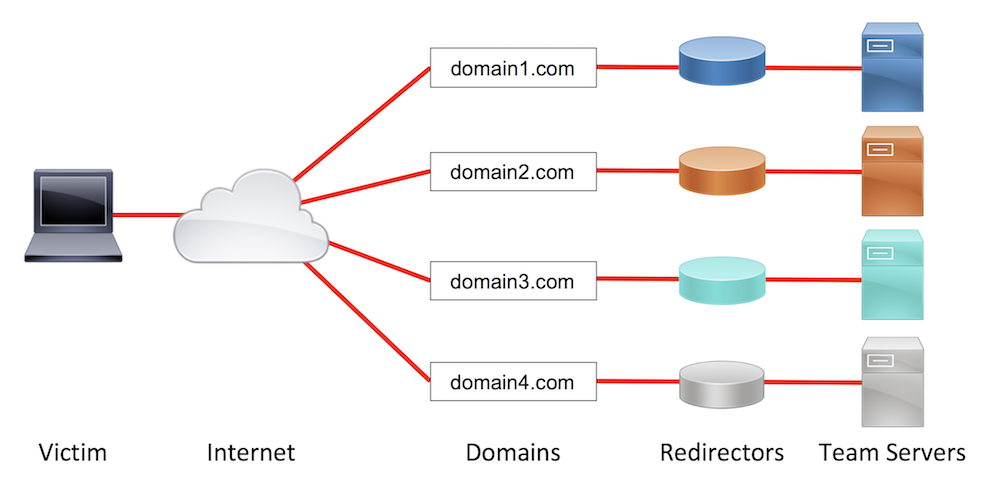
Sample Covert Red Team Attack Infrastructure
In this setup, we have four team servers, rather than one. Each team server is segregated by its duty (i.e. phishing, short-haul C2, and long-haul C2) and has a redirector in front of it to obfuscate the actual team server from the incident responders. This setup, combined with other capabilities covered later, increases the difficulty for blue team responders to block all of the attack infrastructure based on one asset’s discovery.
While this setup may seem complex or likely overkill for a single assessment, the setup provides multiple benefits over a simpler setup. Running individual team servers with customized traffic profiles and tailored protocol choices allows us to blend in with a target organization’s network baselines, hopefully reducing the chances of detection. If the infrastructure is identified as suspicious, leveraging redirectors allows us to perform anti-response actions to limit or completely remove the blue team’s visibility into what our attack infrastructure is doing. Keeping assets segregated innately provides resilience if the blue team begins blocking components in their defensive systems. Finally, this style of attack infrastructure setup provides immense flexibility to adapt to the situations that present themselves as the test progresses.
Design Considerations
Are you sold yet? Great! Now, let’s talk about how to design a covert attack infrastructure. The design process is often involved and requires some testing along the way. Your attack infrastructure should be customized per assessment to the target organization or entity. Red teams customize methodologies, tooling, and attack paths per target environment. Attack infrastructure should be no different.
General
Segregation - All assets should be segregated by function. Typically, these functions are payload hosting, email phishing origination, short-haul C2, and long-haul C2. For more about short-haul vs. long-haul servers, check out Raphael Mudge’s post Infrastructure for Ongoing Red Team Operations. In short though, short-haul servers should be used for primary operating, while long-haul servers should be used primarily for persistence and regaining access to the network. You will likely have multiple instances of each asset in use at a given time. Each individual asset should be configured in a way that allows a single component to be rolled when it gets burned (detected or blocked) by the blue team without impacting the attack infrastructure. For instance, if an email phishing campaign is burned, a blue team should not be able to block your C2 by blocking the domain that originated the email (the from address).
Redirectors - Use a redirector of some kind in front of every backend server. Redirectors provide obfuscation for our backend team servers and can provide some advanced filtering options, depending on the redirector type, that can further hamper blue investigations.
Overkill - Don’t overdo your design. The attack infrastructure should be as complicated as needed to achieve its goals, without throwing every trick in the book at the blue team. We don’t want to overwhelm the blue team or cause a failure on our side due to a needlessly complicated setup. If your test is performing defensive capability testing (like all red team assessments should!), it’s a good idea to build the infrastructure to serve those tests as best as possible.
Try to Counter Controls in Play - Where possible, try to build in defenses against blue team controls or try to subvert the process entirely. For example, if during a pre-phishing campaign you determine the target organization has an email appliance that uses a user agent for an outdated operating system, redirecting matching requests for your phishing website or payload can help your phish land in email inboxes.
Test Length - Keep the test length in mind when designing your infrastructure. A one month test has vastly different requirements than a year-long assessment. For instance, a one-month test may only leverage one persistence mechanism deployed to a handful of servers, whereas a long-term assessment may need multiple persistence mechanisms spread across dozens of hosts.
Testing - Infrastructure primitives should be stress-tested before implementation into your infrastructure. Test for latency, performance under load, potential network detections, and difficulty of setup. It only takes one time accidentally tasking a DNS Beacon with a command that returns a good deal of output to realize why testing and knowing your tools is important.
Rolling New Infrastructure - Segments of your infrastructure will be burned during the course of your assessment. It’s important not to get too attached to any given setup and be willing to roll the infrastructure when it’s determined that the blue team has blocked or investigated the segment to the point that it risks the rest of the infrastructure in play.
Document Everything - Every piece of your attack infrastructure should be thoroughly documented. At a minimum, each asset’s hostname, IP, protocol in use, destination, communication/Malleable C2 profile, and provider should be documented. Essentially, anything you or your client may want to know about the attack infrastructure should be recorded outside of the servers themselves. While documentation is boring to maintain, the complexity of even a simple setup can lead to major problems when on-the-fly modifications are needed or questions pop up after the assessment is completed.
Domains
Categorization - Every domain used in your attack infrastructure setup should be categorized, unless you are simulating an adversary who does not use categorized domains. Domain categorization can instantly increase the apparent reputation of your social engineering campaigns or C2 traffic.
Pre-categorized vs. Home-grown - There are two primary methods of getting ahold of categorized domains. The first is to purchase domains that have already been used legitimately and gone through web categorization before. The categorization remains in place until a domain is submitted for re-rating, such as by the blue team during the assessment. The other method is to buy uncategorized or new domains and get them categorized yourself. Typically, this is done by buying multiple domains, redirecting requests to a fake page masquerading as a page within the target web category, and submitting the domain to multiple categorization engines. The benefit of this method over buying pre-categorized domains is that you can buy exactly the domain you want, rather than relying on the available supply, and age the domains longer than is typically done with pre-categorized domains. However, this method comes at an increased money and time resource cost.
Choosing Domains - When choosing a domain, the most important consideration is finding a domain that will either blend in with the target environments baseline web traffic or fit with the social engineering campaign on which it will be used. In general, strong choices include domains that impersonate the target domain (typosquatting or lookalike domains), domains similar to popular services (i.e. Google, Microsoft), or genericized industry domains (i.e. stock tip domains for a target investment company). It’s important to note that choosing a domain that looks like a well-known company can potentially open you up to having action taken against you to reclaim the domain or seek damages. Be sure your organization accepts that risk before buying lookalike domains for non-target entities.
Payloads
Choosing a Payload - Some commonly-used payload types (at time of writing) include HTML Applications (HTAs), Embedded OLE objects in Office documents, Office macros, and Windows shortcut (LNK) files. Payload execution is a fast-changing game of cat and mouse between attackers and EDR products, so it’s important to stay up-to-date on what generally works in corporate environments, and, if possible, what is likely to work in your target’s environment. Any information about the control environment you can gather during OSINT could help you make an educated guess about the best option to use. A key part of the payload selection process is understanding what the different payload types are doing under the hood and how security controls typically detect (or fail to detect) those actions.
Delivery Methods - In email phishing, there are two primary methods of payload delivery: attachments and download links. In a mature environment, attachments are typically evaluated by some kind of anti-virus solution. Often, these solutions run the payload in a sandbox to determine if the attachment is malicious. Payloads served via download link can also be downloaded by these AV solutions and evaluated in a sandbox. Steps should be taken in your payload and delivery method to reduce the risk of these solutions flagging on your payload. Download links provide some key benefits over attachments, however. Download link payloads can be hot-swapped if you determine the initial payload isn’t working on hosts, payload server access logs can provide very valuable insight into the blue team’s response process, counter-response actions can be taken against those processes using redirection. Download links can be hosted on web servers you control or on cloud storage services, if you accept the risk of potentially breaking Terms of Service, for added domain reputation.
Payload Redirection - Payload redirectors should be used in front of all team servers hosting your social engineering payloads. Web redirectors fall into two major buckets: “Dumb pipe” and filtering. “Dumb pipe” redirectors (i.e. socat and iptables) take traffic received on one port and blindly proxy it to another IP and/or port. All connections are forwarded, regardless of what’s contained within the request and these redirectors often provide limited logging by default, reducing your ability to monitor traffic. Filtering redirectors (i.e. Apache mod_rewrite and nginx) allow each request to be acted upon based on different attributes in the request, such as request URI or user agent. These redirectors provide methods to build out some very strong obfuscation to your backend infrastructure and allow you to potentially subvert the blue team’s investigation or response. Filtering redirectors are often the better choice, but they do take longer to configure and can be difficult to set up if you are using a complex filtering ruleset.
Access Control Options - If you will be performing payload redirection on download links, consider building some access controls into your payload to prevent every blue teamer and investigative solutions that gets ahold of your malicious link. Effective access control options include IP or fingerprint-based redirections, expiring payload links, and invalid URI redirection. The protections you build into your redirectors will likely evolve as the assessment continues and you observe how the blue team is responding to your attacks.
C2
Long-Haul vs. Short-Haul - Long and short-haul C2 servers were briefly covered in the General section above; however, to reiterate: long-haul servers should be used only to regain access into the environment. The servers should receive callbacks from persistence and receive check-ins very slowly, such as one check-in per twelve hours. Short-haul servers are the servers used for all primary operating. These servers will be burned frequently and require the most rolling. The servers should check in much more frequently than the long-haul servers, but not interactively most of the time. Consider using different short-haul servers in different segments of the target environment that have more security controls in place.
Number of Servers - The number of backend C2 servers you will need largely depends on the length of the assessment and how much response you expect from the blue team. Longer assessments usually need additional long-haul servers and may need additional short-haul servers live at once. During the initial access phase of the assessment, you will likely want extra short-haul servers set up to be able to quickly roll burned infrastructure and continue phishing.
Choosing a Protocol - The C2 protocol you use is probably the most important aspect of designing your infrastructure’s C2 strategy. The most common C2 protocols are HTTP(S), DNS, Domain Fronting, and C2 over popular third-party services. Each protocol has its own strengths and weaknesses and their associated detections often function differently. It’s crucial to test the C2 protocols (with redirectors) you plan to use on the assessment by performing a variety of operations, latency, and stress tests. Tests should include running common post-exploitation actions and performing some uploads/downloads.
Though anecdotal, the following chart shows some of the strengths and weaknesses of the common C2 protocols:
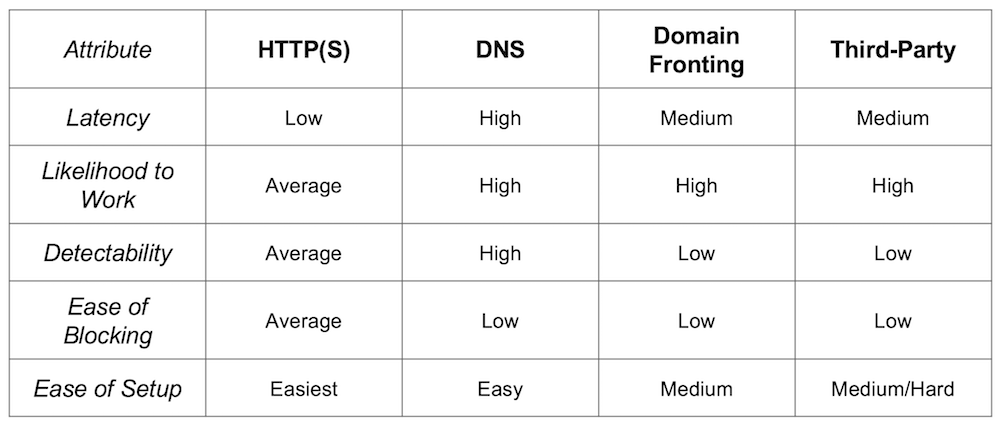
Chart of Common C2 Protocols
Traffic Shaping - Traffic shaping provides very powerful options to make your traffic blend in on the target environment, emulating real applications or specific threat actors. Post-exploitation frameworks offer their own unique traffic shaping optional; however, they commonly allow request URIs, user agents, headers, and parameters to be modified. All servers should take full advantage of traffic shaping options with a customized profile unique to each server.
C2 Redirection - C2 redirection is similar to payload redirection in practice. It aims to obfuscate the backend C2 servers and potentially confuse or disorient the blue team from investigating the traffic. C2 redirection can use the same methods as payload redirection (“dumb pipe” and filtering), but you can also use Domain Fronting or third-party services as C2 redirectors. Support for the latter two options vary per post-exploitation framework, but they provide C2 traffic that is both difficult to detect and difficult to block. The level of C2 redirection you implement should be dictated by the expected or experienced level of response from the blue team and how much resource can be dedicated to implementation and testing.
SMTP
Ideally, your SMTP server (or service) will not reside on the same host as your phishing origination. This allows you to use the same origination platform across all campaigns, rather than needing to deploy the platform for each new phishing campaign. This helps reduce the time and resource spent pulling and preserving multiple sets of logs and reduces the number of overall assets in play.
Self-Setup -The first option for SMTP is to set up your own server to actually send the phishing emails. The sending program is ultimately a personal choice, though if you are planning to use a phishing platform, be sure the sending program works with the platform you’re using. Popular choices include Sendmail and Postfix. Every self-setup SMTP server should be configured with DKIM, SPF, and PTR records. The server should also be configured to drop all previous host headers to avoid disclosing your backend infrastructure IPs. This method is the most time-intensive, but you do control the infrastructure.
Third-Party - Using a third-party service instantly gains sender reputation; however, using the service for phishing may violate the Terms of Service and open you up to the potential of consequences by the provider. Be sure you accept those risks before using this method. Third-party email services often implement controls to prevent spam origination, such as rate limiting or periodic verification if too many messages are sent. It’s a good idea to test sending multiple emails from the service before launching the test.
Open Relay - The third, and most rare, option is finding an unintentionally open mail relay. Real attackers often use mail relays not related to the target organization; however, that’s not advisable for legitimate testing. If you identify an open mail relay owned by your target organization, this would be a very interesting phishing origination server to use and likely would improve your phishing emails’ reputation. Using the open relay will likely require some trial and error to determine which anti-spam controls are implemented and who can originate or receive emails from the relay. Some organizations will allow outside relay only to the internal mail domain, which is exactly what we typically need as red teamers.
Example Infrastructure Diagrams
The following three examples go through a series of scenarios for designing covert red team attack infrastructures and incorporate some of the design considerations discussed above. The goal being to demonstrate how individual infrastructure tricks fit together to maximize the chance of gaining our foothold on a realistic target environment.
Example Design #1
In the first example target organization, OSINT and preliminary discovery phishing revealed:
- Email attachments are blocked
- Email appliances are used to review incoming emails
- The email appliances crawl all links in emails
- No intel about web browsing restrictions
- There are both Windows and macOS hosts in use
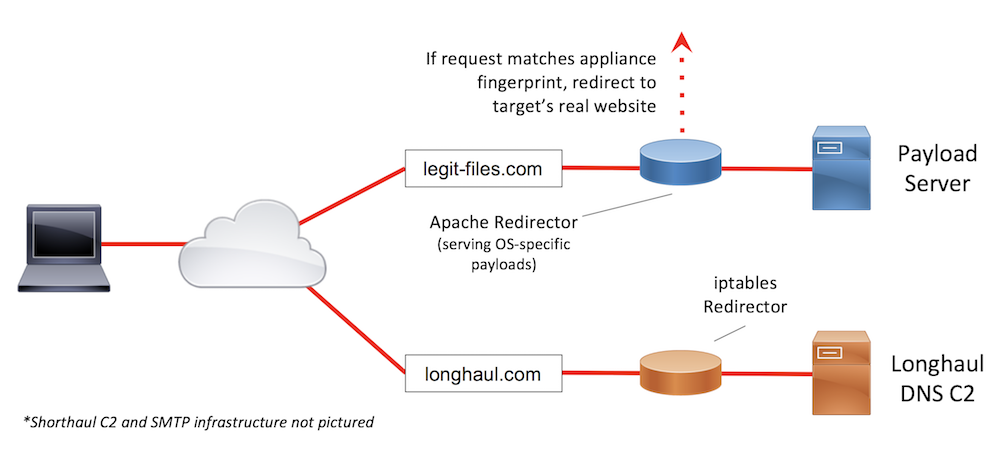
Sample Infrastructure Design #1
In this scenario, we will host our payloads and provide links to the payloads in the phishing emails, since attachments are blocked outright. During the discovery phishing email (an email sent to test and fingerprint controls, rather than attempt to gain access or credentials) we observed an email appliance crawling all links contained in the message body. Reviewing log requests when an email appliance is in use can often yield a discernible fingerprint that can be used to redirect all requests from that appliance to a benign resource, such as a 404 page. A common fingerprint to look for in these appliances is an irregular (or outdated) user agent. With Apache mod_rewrite, we can redirect requests with the appliance’s fingerprint to the target’s 404 page. This will increase the chances of our emails being allowed through the appliance and not marked as spam. Given the mixed OS environment, we can also use the Apache mod_rewrite payload redirector to serve OS-specific payloads to our phishing victims. Finally, since we found no intel about web browsing restrictions, which could potentially block our HTTP-based C2, we can leverage a DNS long-haul C2 server to maximize our chances of getting out.
Example Design #2
In the second example target organization, OSINT and preliminary discovery phishing revealed:
- About half of the users in the environment don’t have internet access
- Those with internet access are heavily restricted
- Publicly-accessible webmail and remote access logins
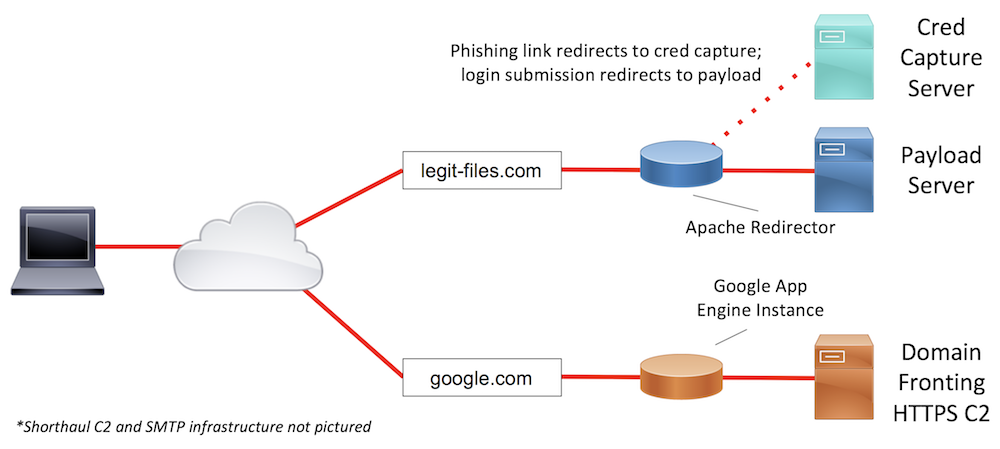
Sample Infrastructure Design #2
In scenario #2, about half of the users don’t have internet access on the production network. In a situation like this, users may fall for the phish but be unable to click our link or execute our payload in the production network. This can typically lead to users using their mobile devices to interact with the phish. Since we likely don’t have mobile-friendly payloads, we will want to send users on mobile devices to a cloned webmail or remote access portal credential capture. Once credentials are captured, it may be possible for us to log into one of the target’s publicly-accessible logins. If not, we at least have credentials, rather than merely a failed payload execution attempt. Given the heavy restrictions on web browsing in the environment, our payload will need to leverage a high-trust domain to maximize the chances of successfully egressing the network. Situations like this are where Domain Fronting shines. We can configure the long-haul C2 traffic to egress the network through the domain google.com and reach our teamserver.
Example Design #3
In the final example target organization, OSINT and preliminary discovery phishing revealed:
- Email attachments are blocked
- The email appliance reviews all links and blocks a wide range of file extensions, but .docx is allowed
- The pre-phishing email campaign was quickly and manually acted upon
- A case study for the target organization’s deployment of a popular online storage service
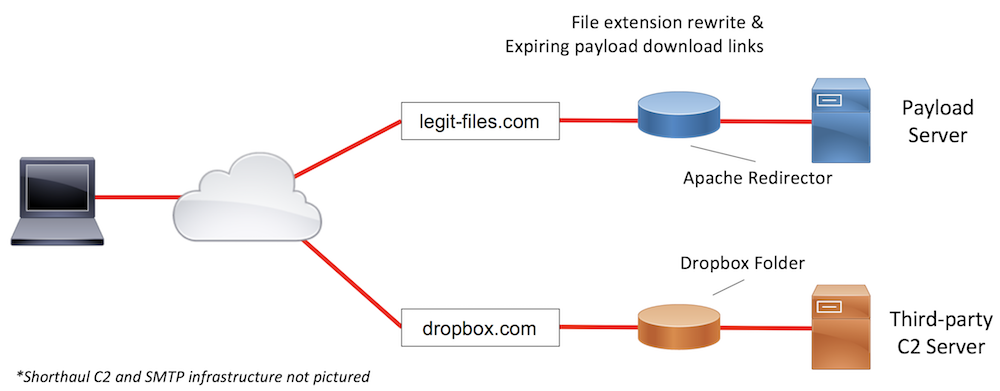
Sample Infrastructure Design #3
The final example situation details a heavily-restricted environment. Again, we will need to leverage web links, rather than attachments, and build in anti-incident response obfuscations into our infrastructure. The email appliance blocking many file extensions, with an exception of at least .docx, we will need to either focus our efforts on a Word document-based payload or perform file extension obfuscation to get the email delivered to the target. The organization’s strong email controls may also mean that web-based controls are strong. Coupling that information with the fact that the target organization has rolled out a popular online storage service in the environment, third-party C2 is a strong choice. That will allow our payloads to communicate with the C2 server over the online storage solution (Dropbox in the example diagram above), which we know the organization allows.
The manual response to the pre-phish indicates a potentially mature blue team we will be trying to outrun. In this kind of attack, we will need to monitor our web logs throughout the assessment and build additional redirections or blocking controls to our infrastructure as the attack progresses. For example, if we start to see requests to a payload link with wget or curl user agents, it’s a likely assumption that: 1) the blue team is manually investigating the phishing email and 2) that email campaign is burned or close to being burned. That indication will tip us off to switch to spending our resources on the next planned email phishing campaign.
Summary
Designing a covert red team attack infrastructure is an important step in launching a successful red team assessment. We don’t use penetration test tradecraft on a red team assessment, so why use infrastructure more suited to a pentest? An effective red team attack infrastructure will segregate its assets and use redirectors (ideally with filtering) in front of every asset. Every asset within the infrastructure should be thoroughly documented and stress tested for operational latency. And finally, the infrastructure should not go overboard; it simply needs to help you achieve your objectives.
Further Resources
- Red Team Infrastructure Wiki
- A Vision for Distributed Red Team Operations - Raphael Mudge (@armitagehacker)
- Infrastructure for Ongoing Red Team Operations - Raphael Mudge
- Advanced Threat Tactics (2 of 9): Infrastructure - Raphael Mudge
- Cloud-based Redirectors for Distributed Hacking - Raphael Mudge
- How to Build a C2 Infrastructure with Digital Ocean – Part 1 - Lee Kagan (@invokethreatguy)